In my previous post, I talked about the importance of goals, objectives and success criteria. Now that we have that information together, we can consider the next part, which is going to be defining the pattern for feeding data into the tests.
The Data
In order for a test to be successful, the system needs to be fed realistic data in a fashion that mimics as closely as possible the type of data that the system will see in production. This can lead to several issues when defining the data that gets fed into the test harness. Things you need to consider about your application are:
- What parts of my data can be re-used? (e.g. Customer last name usually can, but an account number or social security number cannot)
- What data is generated by the system? (e.g. Customer Name is usually provided externally, but a sales receipt ID is created by the system)
- Does my data need to be sanitized? (e.g. If I have customer or PII data, I should not be using it in the test environment, so I might need to generate all of the data that I use in the test.
- If I generate the data, how realistic does it have to be? (e.g. If I add 10,000 users and give them sequential user IDs, that may be perfectly normal if they would be generated sequentially in the real world. However, the likelihood of 10,000 people having sequential social security numbers is very unlikely. This subtle distinction could have a lot of impact when testing search engines or databases that utilize indexing, etc.)
Providing the Data
Test designs that describe the data requirements for a test harness can be broken down into many different styles, but the three that I use the most often are:
- Simple Pre-built Data tests
- Inter-dependent Pre-built Data tests
- Inter-Dependent Self Feeding tests
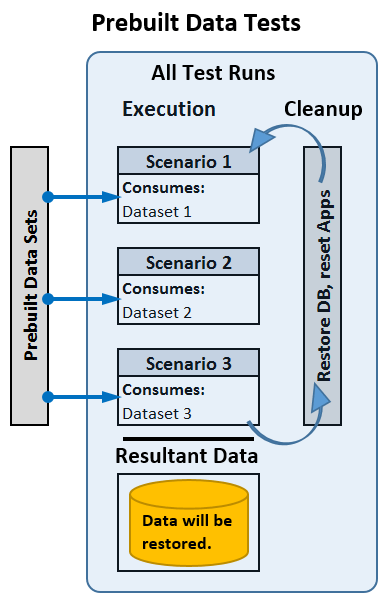
Pre-built Data Tests
Simple Pre-built Data tests – You generate data files to feed into every single test item, and none of the test items depend on any other test item. These are the easiest to build into test software, and usually the easiest to manage, but they are often the most in-accurate and most difficult to maintain. An online shopping site is a good example for this. I need to provide a series of users, have them choose items to order, give them account info to enter when completing the orders and then simply run the tests.
Inter-Dependent Pre-built Data tests are very similar, except that I will have some tests that need to have some data retrieved from the system by work that was already done. The example here would be if we want to simulate a user trying to return an item already purchased, the system being tested would need to already have a record of that sale, and the test data would need to contain the receipt ID (or other ID) to identify the sale in question. Therefore I need to ensure that a sale has already occurred and that I have that info to feed into the test that mimics the “return of an item.”
While these tests are easier to create, they may require you to restore the system after each test, and if you have any requirements for unique data, you will eventually exhaust your data source, so you have to generate enough data to sustain the longest test you plan to execute.
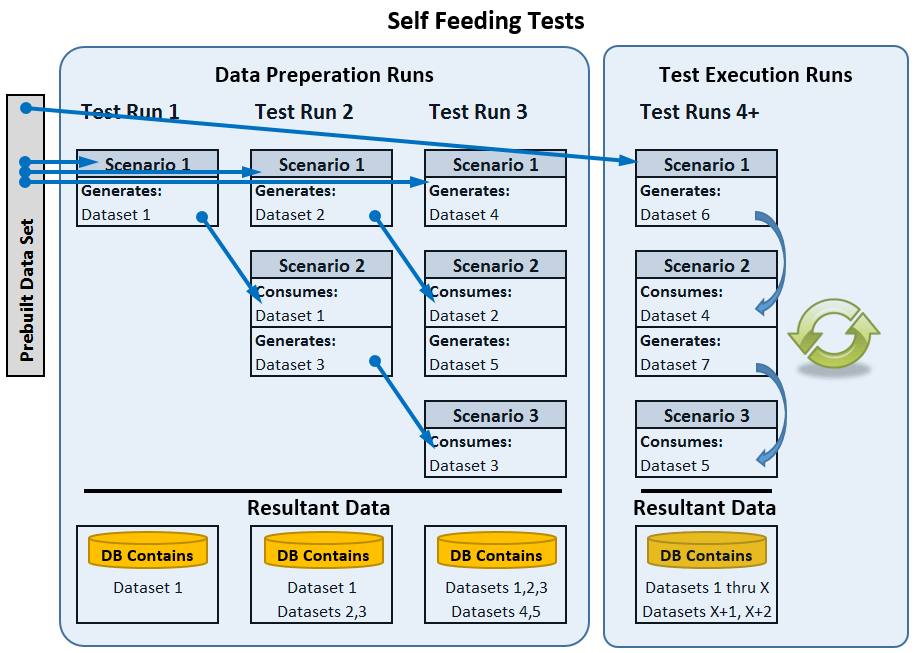
Self Feeding Data Tests
Self Feeding tests assume that some test items rely on previous items and therefore execute the previous items and capture the output of those tests to feed into the other tests. A good example of an application that would benefit from this type of testing is a hospital management app. The first part of the test allows someone to check into the hospital, do insurance, etc. The second part allows the nurses and doctors to help the patient. The third part allows the patient to be checked out and to file insurance. In this case, every part is dependent on the previous part to already be complete.
Self Feeding Data tests are designed in such a way that the tests create the data needed as they execute, allowing the tests to be used as a way of building extra data for the system so that you can watch the performance of a system as the size of data grows, and you can maintain the tests more easily since they create their own data. NOTE: These tests are often the most difficult to build up front because you have to add the ability to collect data during execution and save it for use by the test in future iterations, but they are the most realistic in terms of mimicking real world behavior.
The idea is that you generate one set of seed data, then you feed that into the first part of the test and execute it. That data then will get fed into the second part of the test while you use more seed data to generate the next set of data:
Conclusion
As you can see, we need to understand the nature of the application we are testing and we need to make some decisions up front on how we want to generate and maintain data. These decisions will help decide how we need to model our use cases and scenarios, and eventually how we generate test data and the final test harness. The next two topics in this series will be:
- Proper Use Cases and Scenarios
- Defining [and Implementing] the Final Load
