Below is a list of posting categories. Go to each category to see the posts available in that category. For a complete “Table of Contents” you can use this page.

Formerly the site of Gray Test Consulting, I am now using the site for sharing information about software testing best practices
Below is a list of posting categories. Go to each category to see the posts available in that category. For a complete “Table of Contents” you can use this page.
A single source of truth is an agreed-upon shared location where information about requirements, defined processes, working agreements, and other important information can be easily found, used and updated as needed.
A good example of a SSOT is the stories (or PBIs) in the backlog. They define the intent of the product team and the specifics needed for the dev team to implement the desired functionality. Another SSOT is the code itself. In fact, the code is the ultimate SSOT. However, what does the team do for those pieces of information that do not belong in a work item or the code? A good example of a “process” SSOT is a WIKI. A wiki allows items to be updated as needed, commented upon, and have a revision history for accountability. WIKIs in ADO can be viewed by everyone on the team, as well as people outside the team. They can be searched. Etc.
The biggest argument I hear about implementing an SSOT is that it conflicts with one of the four principles of the Agile Manifesto: “Working Software Over Comprehensive Documentation” but I believe there is no conflict. I say this because a good S.S.O.T. is not comprehensive. In fact, a well designed S.S.O.T. should be simple enough to build quickly, use quickly, update quickly, and validate quickly. One of the reasons I push for the use of a WIKI as the location for your S.S.O.T. is because wikis are designed to meet all of the criteria I just mentioned. Let me give you an example:
I was working on a project where there was an issue with unzipped JAR files becoming corrupt during deployment. After discovering the issue, the team agreed to validate the JAR files after unzipping, but they didn’t have a way of reminding themselves to do this step. If they had a checklist for steps when they deployed, it would take about 45 seconds to open the checklist and add the step. Then they would be reminded about it during the next release. Also, if a new person took over the responsibility of releasing, the checklist would provide the steps to follow.
After a recent presentation at work on testing fundamentals, I was asked a question about testing that I felt really deserved a full blog post. The question was “What suggestions do you have to identify blind spots during testing? The person added:
“The question comes from the challenge I sometimes face which is: the source code does not always tell the whole story; half of the “context” is set by the system configuration, the business transactional data and the business processes in SAP. I would like to ensure that a change request does not impact inadvertently other areas (e.g. business or system data).”
This is an area of testing I have dealt with most of my career since I specialized in perf and load testing for so long, but often this is overlooked by agile teams or functional testing environments in complex business apps. Unfortunately, by not accounting for it in testing plans and/or working agreements, the testers are often at the mercy of unknown issues/changes/configs/etc. The answer is simple to explain, but it is often extremely difficult to implement. The first part of this post will explain what I consider to be the best way to approach this issue, and the second part will give you some tips on dealing with potential implementation impediments.
To know what a tester is responsible for when executing tests and analyzing results, the tester must know the boundaries where his or her team can affect changes. These boundaries include:
Once the boundaries are defined, the team can now negotiate with the owners of the other areas and the product team to define how testing will proceed.
Let’s look at an example system. We will use an example where four apps are all hitting the same shared SAP and CRM system, all using shared auth. Let’s assume the developers and testers only have access to application 1. How do they handle all the items listed above?
Have a known AND RELIABLE change control system in place that makes it easy for dev teams to see (and understand) the changes and their impact on the system overall. Ensure that changes to the system are only rolled out at known times so testers can plan accordingly.


If the data is not specifically needed to complete a test, then the data should be considered as Not our responsibility and therefore does not need to be considered. If, however, it is needed for test completion, then it should be treated as test data. The next section explains handling test data.

Here I am showing four sets of test data, as well as four pieces of system data that are needed for the test data to be used properly. In this case, you have to figure out if this data is going to be shared or will belong to the team.
Test Data 1 is assumed to “belong” to the dev team and therefore does not constitute a boundary. Datum 2 through 4 are shared, so coordination will have to occur.

When an application is self-contained, it is easier to control the code that exists in various parts of the application. But when things are shared, there is a need to track the versions and/or the interfaces that are exposed in dev, test and prod environments. Below we can see that team 1 cannot test fully, but teams 2-4 can. In this case, team 1 would rely on shims or mocks to test and would align the full testing by coordinating with the broader teams the same way we do in the “Parts of the System” section.

Here is the final complete diagram, showing all of the potential boundaries that the development team may encounter.
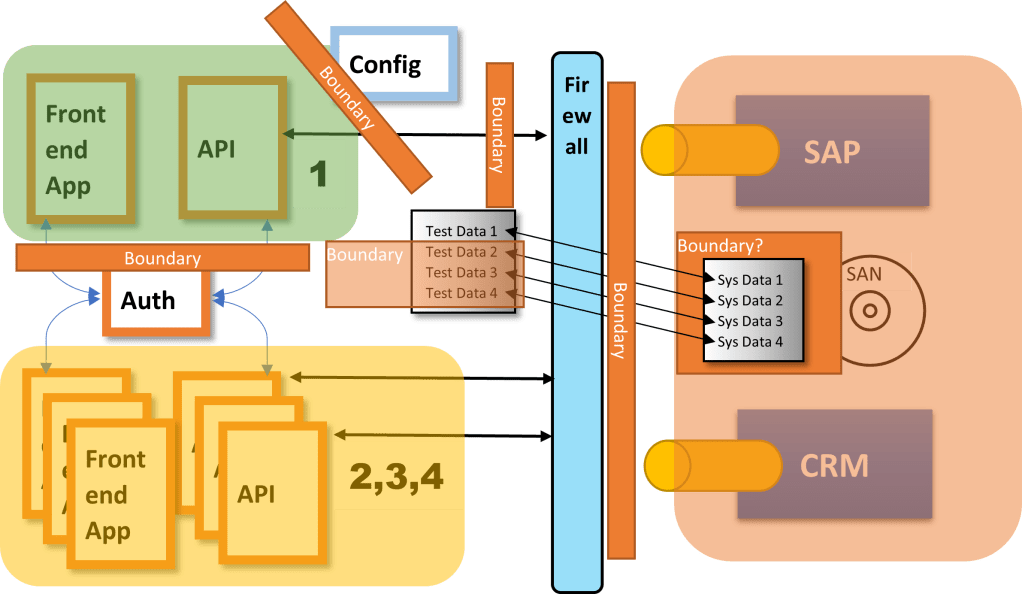
By defining every boundary, and then discussing each with the team(s) that own the items on the other side of the boundaries, you can start to negotiate appropriate ways of dealing with the issues. As you negotiate this, remember that it is important to account for the amount of effort involved in each decision. If your team has to take on more responsibility, then your velocity will slow down. Make sure the product owners are aware of these trade-offs and are willing to accept them, or to find ways to mitigate them.
In software development, we use requirements to state what must (or must not) be a part of the outcome of a project. We also use requirements to define the purpose of testing (e.g. “what is it that you expect to accomplish by testing”). Requirements show up in all the major development frameworks, albeit sometimes wearing different names (VSTS uses “Product Backlog Items” for Scrum, “User Stories” for Agile, and “Requirements” for CMMI).
However, consequences are rarely listed as part of the documentation in any of the models I have seen.
These posts cover various items about how Visual Studio Web and Load Testing features work, common questions about what settings to use, where and when to put forth extra effort and why different behaviors may be important to consider.
This series of posts covers information about the various steps that go into planning for load testing an application.
This series of posts covers topics on how data is stored and calculated, as well as what items are important when generating your reports.
This series of posts dissects the Visual Studio Load Testing Results Database.
Here you will find downloadable items which can help make your testing work easier.
